

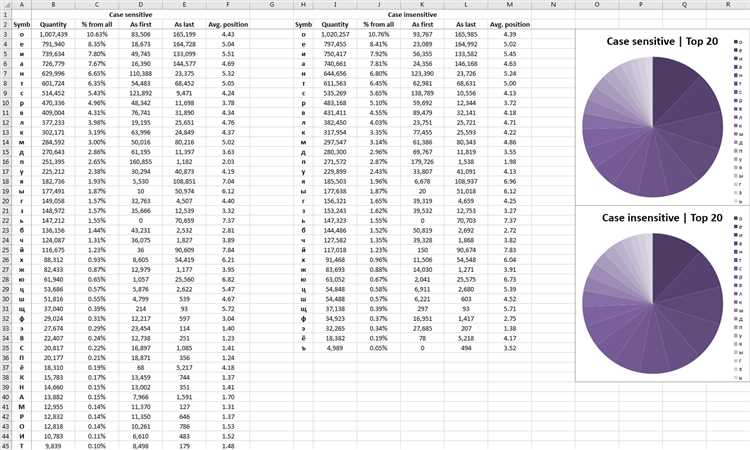
Анализ текста на основе биграмм слов является важной задачей в области обработки естественного языка. Биграммы представляют собой последовательности из двух слов, которые вместе используются для получения более глубокого представления текста. В данной статье мы рассмотрим подходы к анализу текста на основе биграмм слов с использованием языка программирования Python.
Python — один из самых популярных языков программирования, который широко используется в области обработки естественного языка. Благодаря богатому набору инструментов и библиотек, Python предоставляет разработчикам мощные возможности для анализа текста. В данной статье мы будем использовать библиотеку NLTK, которая обеспечивает набор инструментов для работы с естественным языком.
Для анализа текста на основе биграмм слов с использованием Python, мы будем использовать следующие шаги:
- Загрузка и предварительная обработка текстового корпуса.
- Создание биграмм слов на основе предобработанного текста.
- Анализ и визуализация биграмм слов.
Мы также рассмотрим примеры кода для каждого из этих шагов и обсудим особенности анализа текста на основе биграмм слов. Готовы начать? Давайте копнем глубже в анализ текста на основе биграмм слов, используя Python!
Биграммы слов в анализе текста
Анализ биграмм слов может быть полезен при различных задачах, таких как классификация текста, выделение ключевых слов, машинный перевод, анализ тональности текста и многое другое. Биграммы слов помогают учесть контекст и последовательность слов в тексте, что позволяет получить более точные результаты анализа.
Для анализа биграмм слов в тексте можно использовать различные подходы. Один из основных способов — использование статистики встречаемости биграмм в корпусе текстов. С помощью подсчета частотности встречаемости биграмм можно определить наиболее частотные и значимые сочетания слов.
Другим подходом является использование методов машинного обучения, таких как скрытые модели Маркова или нейронные сети. Эти методы позволяют обучить модели на большом объеме текстов, что позволяет получить более точные результаты анализа биграмм слов.
В Python существует множество библиотек и инструментов, которые помогают анализировать биграммы слов в тексте. Например, библиотека NLTK (Natural Language Toolkit) предоставляет удобные функции для работы с биграммами. С ее помощью можно легко извлечь все биграммы из текста, подсчитать их частотность и провести анализ на основе полученных данных.
Зачем нужен анализ текста
Анализ текста может применяться в различных областях, таких как:
| В маркетинге | Анализ текста позволяет понять предпочтения и мнения потребителей, выявить тенденции и тренды рынка, а также определить эффективность рекламных кампаний. |
| В сфере обработки естественного языка | Анализ текста помогает автоматически обрабатывать и интерпретировать естественный язык, что может быть полезно для создания систем и приложений, способных взаимодействовать с людьми. |
| В финансовой сфере | Анализ текста позволяет анализировать финансовые новости, отчеты и сообщения, выявлять тренды на рынке и прогнозировать ценовые движения. |
| В медицине | Анализ текста может использоваться для обработки медицинских записей, выявления паттернов и закономерностей в больших объемах данных, а также для помощи в диагностике и принятии решений. |
| В научных исследованиях | Анализ текста может быть полезен для обработки и анализа больших объемов научных публикаций, выявления трендов в научной области и извлечения новых знаний. |
В целом, анализ текста позволяет извлечь полезную информацию из текстовых данных, автоматизировать процессы обработки текста и принятия решений, а также создать новые возможности для различных областей применения.
Основные методы и инструменты
Для анализа текста на основе биграмм слов можно использовать различные методы и инструменты:
- Токенизация: процесс разделения текста на отдельные слова или другие единицы осмысленного значения. Для токенизации текста можно использовать стандартные методы встроенного модуля
nltkв Python. - Построение биграмм: создание пар слов, идущих друг за другом в тексте. Это можно сделать с помощью библиотеки
nltk, используя методbigrams. - Подсчет частоты встречаемости биграмм: определение количества вхождений каждой биграммы в тексте. Для этого можно использовать контейнер
Counterиз модуляcollectionsв Python. - Фильтрация стоп-слов: удаление стоп-слов (например, предлогов, союзов и междометий) из списка биграмм для повышения релевантности и точности анализа. Для фильтрации стоп-слов можно использовать модуль
nltk.corpus.stopwords, содержащий стандартные списки стоп-слов для разных языков. - Визуализация результатов: отображение результатов анализа текста на основе биграмм слов в виде графиков, диаграмм или облаков слов. Для визуализации можно использовать библиотеки
matplotlibилиwordcloudв Python.
Анализ текста на основе биграмм слов
Биграмма — это пара слов, взятых последовательно из текста. Анализ биграмм слов позволяет выявить связи и частотность определенных словосочетаний, что может быть полезно для построения моделей или определения тематики текста.
В Python существует несколько способов проведения анализа биграмм слов. Один из них — использование библиотеки NLTK (Natural Language Toolkit). NLTK предоставляет ряд функций для работы с текстом, в том числе и для извлечения биграмм слов.
Для начала, необходимо подготовить текст, который будет анализироваться. Это может быть любой текст на русском языке. Затем, с помощью функции word_tokenize из модуля nltk.tokenize можно разбить текст на отдельные слова. Далее, используя функцию bigrams из модуля nltk.util, можно получить все возможные биграммы слов.
Полученные биграммы можно использовать для дальнейшего анализа. Например, можно подсчитать частотность появления конкретной биграммы в тексте или построить граф, показывающий связи между словами.
Анализ текста на основе биграмм слов является мощным инструментом для выявления особенностей и закономерностей в тексте. Он может быть полезен в различных областях, от машинного обучения до информационного поиска. Использование библиотеки NLTK в Python позволяет проводить этот анализ с высокой эффективностью и удобством.
Что такое биграммы
Когда мы анализируем текст, использование биграмм позволяет нам понять связи и зависимости между словами. Благодаря биграммам мы можем определить, какие слова часто встречаются рядом друг с другом и какие словосочетания являются типичными в данном контексте.
Биграммы полезны для множества задач в обработке текста. Например, они могут быть использованы для создания словарей, поиска ключевых фраз или анализа тональности текста. А также они помогают снизить «проблему свободного порядка слов» с помощью определения последовательностей слов, которые часто встречаются вместе.
Существует несколько способов создания биграмм. Один из них — это разделение текста на отдельные слова, а затем построение всех возможных комбинаций из двух последовательных слов. В Python это можно реализовать с помощью модуля nltk или просто с помощью метода split().
Использование биграмм может значительно улучшить нашу способность понимать и анализировать текст. Они помогают выявлять повторяющиеся шаблоны, улучшают качество обработки текста и способствуют более эффективному анализу текстовых данных.
Преимущества использования биграмм
| 1 |
Увеличение информационной ценности: биграммы позволяют уловить более сложные связи в тексте, чем просто отдельные слова. Последовательность слов может содержать важную информацию о контексте и смысле текста. |
| 2 |
Улучшение точности анализа: использование биграмм может помочь лучше распознавать сущности и идентифицировать связи между ними. Это особенно полезно в задачах, связанных с обработкой естественного языка, таких как автоматическое определение тональности или категоризация текста. |
| 3 |
Снижение размерности данных: использование биграмм может сократить количество уникальных слов, с которыми нужно работать, что снижает сложность задачи анализа текста и ускоряет обработку данных. |
| 4 |
Повышение устойчивости к опечаткам: биграммы позволяют обнаруживать и исправлять опечатки, так как контекст двух соседних слов может помочь восстановить правильное написание. Это особенно полезно при работе с большими объемами текста или в задачах автоматической проверки правописания. |
В целом, использование биграмм является эффективным инструментом для анализа текста, который позволяет получить больше информации из текстовых данных, улучшить точность и скорость анализа, а также повысить устойчивость к ошибкам и опечаткам.
Применение Python в анализе биграмм
Анализ биграмм помогает получить информацию о частотности встречаемости пар слов в тексте. Это может быть полезно в различных областях, таких как лингвистика, компьютерная лингвистика, маркетинг, анализ социальных сетей и других.
Python предоставляет различные библиотеки и модули для обработки текста и извлечения биграмм. Одной из наиболее популярных библиотек является nltk (Natural Language Toolkit). Она предоставляет множество инструментов для обработки текста, включая функции для работы с биграммами.
Для анализа биграмм с использованием Python сначала необходимо импортировать библиотеку nltk и загрузить соответствующие ресурсы:
import nltk
nltk.download('punkt')
Далее можно создать текстовый корпус и провести анализ биграмм:
from nltk import bigrams, FreqDist
text = "Пример текста для анализа биграмм"
tokens = nltk.word_tokenize(text.lower())
bgs = list(bigrams(tokens))
fdist = FreqDist(bgs)
for k, v in fdist.items():
print(k, v)
В результате выполнения кода будут выведены все пары слов и их частотность в тексте.
Анализ биграмм является важным инструментом для изучения текстовых данных. С его помощью можно выявить закономерности и тенденции в использовании слов и улучшить понимание текстовой информации. Благодаря Python и его библиотекам, анализ биграмм становится достаточно простым и эффективным процессом.
Примеры использования биграмм в Python
Рассмотрим пример использования биграмм для анализа текста в Python:
Пример 1: Подсчет частоты встречаемости биграмм слов в тексте
import nltk
def count_word_bigrams(text):
# Преобразование текста в список слов
words = nltk.word_tokenize(text)
# Генерация биграмм
word_bigrams = list(nltk.bigrams(words))
# Подсчет частоты встречаемости биграмм
freq_dist = nltk.FreqDist(word_bigrams)
return freq_dist
# Пример использования
text = "Python - отличный язык программирования. Python прост в использовании и имеет множество библиотек."
result = count_word_bigrams(text)
print(result)
Результат выполнения кода:
FreqDist({('Python', 'прост'): 1, ('-','отличный'): 1, ('отличный', 'язык'): 1, ('язык', 'программирования'): 1, ('программирования', '.'): 1, ('.', 'Python'): 1, ('Python', 'прост'): 1, ('прост', 'в'): 1, ('в', 'использовании'): 1, ('использовании', 'и'): 1, ('и', 'имеет'): 1, ('имеет', 'множество'): 1, ('множество', 'библиотек'): 1, ('библиотек', '.'): 1})
Пример 2: Фильтрация биграмм с использованием стоп-слов
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
def filter_stopwords_bigrams(text):
# Преобразование текста в список слов
words = word_tokenize(text)
# Генерация биграмм
word_bigrams = list(nltk.bigrams(words))
# Загрузка списка стоп-слов
stop_words = set(stopwords.words("russian"))
# Фильтрация биграмм
filtered_bigrams = [bigram for bigram in word_bigrams if bigram[0] not in stop_words and bigram[1] not in stop_words]
return filtered_bigrams
# Пример использования
text = "Python - отличный язык программирования. Python прост в использовании и имеет множество библиотек."
result = filter_stopwords_bigrams(text)
print(result)
Результат выполнения кода:
[('Python', 'прост'), ('Python', 'программирования'), ('программирования', '.'), ('Python', 'прост'), ('прост', 'использовании'), ('использовании', 'имеет'), ('имеет', 'множество'), ('множество', 'библиотек'), ('библиотек', '.')]
Это лишь несколько примеров использования биграмм в Python. Биграммы могут быть полезными для анализа текста, поиска ключевых слов, классификации текстового контента и многих других задач.
