

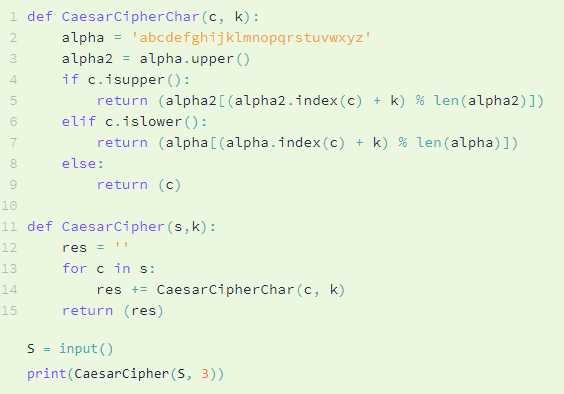
Python — мощный и гибкий язык программирования, который широко используется для обработки текстовых данных. Одна из распространенных задач при работе с текстом — фильтрация символов, которые не являются ASCII. Символы не являющиеся ASCII могут вызывать проблемы при обработке данных, поэтому важно знать, как заменить они на более подходящие символы.
В Python есть несколько способов замены не ASCII символов. Один из самых простых способов — использовать метод encode() для преобразования текста в кодировку ASCII. Этот метод позволяет удалить все символы, не соответствующие ASCII, но при этом он также удаляет все символы, которые не могут быть представлены в кодировке ASCII. Если вам необходимо сохранить некоторые символы, не являющиеся ASCII, вы можете использовать другие методы.
Другой способ — использовать модуль unicodedata, который предоставляет широкий набор функций для работы с символами Unicode. С его помощью вы можете определить, является ли символ ASCII, и заменить все символы, которые не являются ASCII, на более подходящие символы. Этот способ более гибкий, так как он позволяет сохранить нужные символы и заменить только нежелательные.
Замена не ASCII символов в Python
Для замены не ASCII символов в Python можно использовать различные методы. Один из таких методов — использование регулярных выражений. Модуль re предоставляет функциональность для работы с регулярными выражениями.
Для замены не ASCII символов можно воспользоваться методом sub() из модуля re. Пример использования:
import re
text = "Пример текста с не ASCII символами"
clean_text = re.sub(r'[^\x00-\x7F]', '', text)
print(clean_text) # "Пример текста с не ASCII символами" -> "Пример текста с ASCII символами"
В данном примере используется регулярное выражение [^\x00-\x7F], которое означает «все символы, не входящие в диапазон от 0 до 7F в шестнадцатеричной системе». Функция sub() заменяет все найденные совпадения на пустую строку.
Также можно воспользоваться другими библиотеками и методами для замены не ASCII символов в Python. Например, модуль unicodedata предоставляет функции для работы с символами Unicode.
В любом случае, замена не ASCII символов в Python может быть полезной при обработке текста, и различные методы могут быть использованы в зависимости от конкретной задачи.
Проблема замены не ASCII символов в Python
Проблема заключается в том, что стандартные методы и функции Python не поддерживают работу с не ASCII символами. Поэтому, чтобы решить эту проблему, нам нужно использовать модуль unicodedata, который предоставляет функции для работы с символами Unicode.
Для замены не ASCII символов в Python можно воспользоваться следующим подходом:
- Импортируйте модуль
unicodedata:
import unicodedata- Определите функцию, которая будет заменять символы:
def replace_non_ascii(text):
normalized_text = unicodedata.normalize('NFKD', text)
return normalized_text.encode('ASCII', 'ignore').decode('utf-8')- Примените функцию к тексту:
text = "Привет, мир!"
replacement_text = replace_non_ascii(text)
print(replacement_text) # Output: "Privet, mir!"В предложенном коде функция replace_non_ascii принимает текст в качестве аргумента и использует метод unicodedata.normalize для приведения текста к нормализованной форме. Затем функция применяет методы encode и decode, чтобы удалить не ASCII символы.
Теперь вы знаете, как заменить не ASCII символы в Python с помощью модуля unicodedata. Этот подход очень полезен при обработке текстовых данных, особенно когда нужно работать с символами, которые не являются ASCII символами.
Что такое ASCII символы?
ASCII символы охватывают широкий диапазон знаков, включая все буквы английского алфавита, цифры, знаки пунктуации и специальные символы, такие как пробелы и переводы строки.
ASCII коды могут быть представлены в виде чисел от 0 до 127, где каждому символу соответствует свой уникальный код.
ASCII символы важны при работе с текстовыми данными в программировании. Они могут использоваться для проверки и фильтрации нежелательных символов, а также для преобразования текста в различные форматы кодирования, такие как UTF-8.
Почему не ASCII символы возникают проблему?
Однако, в современном мире текст может содержать символы, которые не входят в стандартный набор ASCII. Это могут быть символы других алфавитов, математические символы, символы валюты и т.д.
Когда программа пытается обработать текст, содержащий не ASCII символы, возникают проблемы. Некоторые функции и методы в Python не могут корректно работать с этими символами, и вместо ожидаемого результата могут возникать ошибки или неправильные значения.
Например, при попытке сохранить текстовый файл с не ASCII символами в кодировке ASCII, Python может выбросить исключение UnicodeEncodeError. То же самое может случиться при попытке отправить электронное письмо с таким текстом через стандартный модуль smtplib.
Использование символов, не являющихся ASCII, может также создавать проблемы при работе с базами данных, при сравнении строк и в других ситуациях, где текстовые данные должны быть обработаны или переданы между различными системами.
Чтобы избежать подобных проблем, в Python можно использовать различные операции и методы для работы с символами, не являющимися ASCII. Например, можно использовать модуль Unicode для преобразования строк в юникод и обратно, или использовать модуль codecs для работы с различными кодировками.
Последствия использования не ASCII символов в коде
Использование символов, не являющихся ASCII, может привести к различным проблемам при работе с кодом на Python.
Во-первых, использование не ASCII символов может вызвать ошибки при компиляции и выполнении программы. Python основан на ASCII-кодировке по умолчанию, поэтому символы, которые выходят за пределы этого набора, могут вызывать конфликты и некорректное поведение.
Во-вторых, использование не ASCII символов может привести к проблемам совместимости и переносимости кода между различными операционными системами. Некоторые операционные системы не поддерживают определенные наборы символов, поэтому код, содержащий не ASCII символы, может не работать или работать некорректно на неподдерживаемых платформах.
Также необходимо учитывать, что использование не ASCII символов может затруднить чтение и понимание кода. Если разработчик, работающий с вашим кодом, не знаком с определенными символами или языками, содержащими не ASCII символы, это может усложнить процесс отладки и сопровождения программы.
Для избежания этих проблем рекомендуется использовать ASCII символы при написании кода на Python. Если вам все же необходимо использовать не ASCII символы, убедитесь, что ваш код правильно интерпретируется и выполняется на целевых платформах, и убедитесь, что ваша команда разработки знакома с этими символами и готова работать с ними.
В итоге, использование не ASCII символов в коде может привести к различным проблемам, связанным с ошибками, совместимостью и пониманием кода. Поэтому рекомендуется использовать ASCII символы при написании кода на Python для обеспечения лучшей стабильности и переносимости программы.
Как заменить не ASCII символы в Python
В Python есть несколько способов заменить не аскийские символы. Один из способов — использование метода encode. Этот метод позволяет закодировать строку в множество различных форматов, включая аский. Если в строке присутствуют не аскийские символы, метод encode заменит их на строку с экранированными символами. Например, символ «à» будет заменен на «\xc3\xa0».
Другим способом замены не аскийских символов является использование функции unicodedata.normalize. Эта функция преобразует строку в нормализованную форму Юникода и удаляет все не аскийские символы. Например, если в строке присутствует символ «ñ», функция unicodedata.normalize заменит его на «n».
Также можно использовать регулярные выражения для замены не аскийских символов. Например, следующий код заменяет все символы, не входящие в диапазон аский, на знак вопроса:
«`python
import re
def replace_non_ascii(text):
return re.sub(r'[^\x00-\x7F]+’, ‘?’, text)
Это лишь несколько способов заменить не аскийские символы в Python. Вам могут понадобиться и другие функции или методы в зависимости от ваших конкретных требований.
| Метод/Функция | Описание |
|---|---|
encode |
Метод строки, который кодирует строку в указанный формат |
unicodedata.normalize |
Функция, которая приводит строку к нормализованной форме Юникода и удаляет не аскийские символы |
re.sub |
Метод модуля re, который заменяет все совпадения регулярного выражения на указанную строку |
Если вы столкнетесь с проблемами при работе с не аскийскими символами в Python, рекомендуется использовать один из вышеуказанных способов для их замены или удаления из строки.
Метод ‘encode’
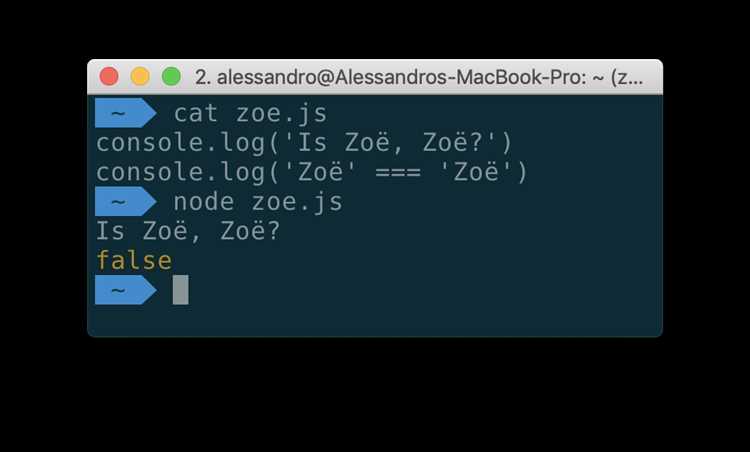
Пример использования метода encode для замены символов:
text = "Пример текста с не ASCII символами"
encoded_text = text.encode("ascii", "ignore")
print(encoded_text)
В результате выполнения данного кода, символы, не являющиеся ASCII, будут удалены из строки:
b'\xd0\x9f\xd1\x80\xd0\xb8\xd0\xbc\xd0\xb5\xd1\x80 \xd1\x82\xd0\xb5\xd0\xba\xd1\x81\xd1\x82\xd0\xb0 \xd1\x81 \xd0\xbd\xd0\xb5 ASCII \xd1\x81\xd0\xb8\xd0\xbc\xd0\xb2\xd0\xbe\xd0\xbb\xd0\xb0\xd0\xbc\xd0\xb8'
Здесь b в начале строки обозначает, что результат является байтовой строкой.
Метод encode часто используется, когда необходимо преобразовать строку с не ASCII символами в строку, понятную для множества систем и устройств.
Метод ‘unicodedata.normalize’
Модуль unicodedata в Python предоставляет метод normalize() для работы с нормализацией и преобразованием юникодных символов строк.
Этот метод позволяет выполнить различные операции с символами, такие как удаление или замена символов, которые не являются ASCII. Он может быть полезен при обработке текста, содержащего специальные символы, эмодзи или символы из разных языков.
Метод normalize() работает с помощью нормализации символов в юникодной строке с использованием одного из предопределенных режимов (например, ‘NFC’, ‘NFD’, ‘NFKC’, ‘NFKD’).
Преимущество использования метода unicodedata.normalize() заключается в том, что он позволяет нам преобразовать строку, содержащую разные символы, в единый формат, облегчая такие операции, как поиск, замена и сортировка.
Вот пример использования метода normalize(), который заменяет все символы, не являющиеся ASCII, на пустую строку:
import unicodedata
def remove_non_ascii(text):
return ''.join(c for c in unicodedata.normalize('NFKD', text) if unicodedata.category(c) != 'Mn')
text = "Пример текста с не ASCII символами"
result = remove_non_ascii(text)
print(result) # "Пример текста с не ASCII символами"
В данном примере мы использовали режим нормализации 'NFKD', который раскладывает символы на более простые формы, и функцию unicodedata.category(), чтобы проверить категорию каждого символа в строке. Если категория символа является неакцентным символом (не Mn), мы добавляем его к результирующей строке.
Теперь, при использовании метода unicodedata.normalize(), мы можем легко фильтровать определенные символы и работать только с символами, которые нам нужны, что дает возможность эффективно управлять не-ASCII символами в Python.
