

XML (Extensible Markup Language) является одним из наиболее популярных форматов для обмена данных и хранения информации. Python предоставляет мощные инструменты для работы с XML, а одним из наиболее популярных инструментов является библиотека ElementTree.
ElementTree позволяет считывать, создавать, редактировать и сохранять XML-документы с помощью простого и интуитивно понятного API.
Одной из ключевых концепций обработки XML в ElementTree является использование пространства имен. Пространства имен могут быть полезными, когда вам нужно избежать конфликтов имен между элементами или атрибутами в разных XML-документах или разделах XML-документа.
В этом руководстве мы рассмотрим, как использовать ElementTree для работы с пространствами имен в Python 3.
Мы покажем вам, как определить пространства имен, как использовать их при создании XML-элементов, и как осуществлять поиск элементов с использованием пространств имен.
- Что такое пространство имен в XML?
- Определение пространства имен
- Преимущества использования пространства имен
- Как использовать ElementTree для обработки пространства имен в Python 3?
- Установка библиотеки ElementTree
- Загрузка и парсинг XML-файла с помощью ElementTree
- Извлечение данных из XML-файла с пространством имен
Что такое пространство имен в XML?
Пространства имен в XML предназначены для организации и разграничения элементов и атрибутов в документе, чтобы избежать возможных конфликтов между именами. Каждый элемент или атрибут может быть связан с пространством имен, которое определяет его уникальность.
Пространства имен в XML обозначаются специальными префиксами перед именами элементов и атрибутов, например:
<books:book xmlns:books="http://example.com/books">
Здесь префикс «books» является пространством имен, а URL «http://example.com/books» – его идентификатором. Это позволяет однозначно идентифицировать элемент «book» в пределах данного пространства имен.
Пространства имен могут быть использованы для группировки элементов и атрибутов с общим назначением, для добавления контекста и семантики к данным XML, а также для интеграции различных форматов и стандартов данных.
Пространства имен имеют важное значение при обработке XML в Python с помощью ElementTree, поскольку позволяют точно определить и обращаться к элементам и атрибутам в XML-документах.
Определение пространства имен
Для того чтобы работать с пространствами имен в XML с помощью модуля ElementTree в Python, необходимо понимать основные понятия и методы.
- Пространство имен задается с помощью пары (префикс, URI), где префикс – это короткое имя, а URI (Uniform Resource Identifier) – уникальный идентификатор ресурса.
- ElementTree предоставляет методы для работы с пространствами имен, такие как: register_namespace(), QName(), iterparse() и т. д.
- Префикс пространства имен связывается с URI в корневом узле XML-документа, и все его потомки могут использовать этот префикс для обращения к элементам, определенным в данном пространстве имен.
Важно помнить, что при работе с пространствами имен нужно учитывать возможные конфликты имен, а также правильно настраивать их для каждой конкретной задачи.
Преимущества использования пространства имен
Преимущества использования пространства имен в XML-обработке с помощью ElementTree в Python 3:
- Уникальность имен: Пространство имен позволяет гарантировать, что имена элементов и атрибутов являются уникальными в рамках XML-документа. Это позволяет избежать конфликтов и путаницы при обработке данных.
- Сопоставление схемам: Пространство имен обеспечивает возможность связать элементы и атрибуты XML с определенными схемами или пространствами имен. Это упрощает валидацию данных и проверку их соответствия заранее заданным правилам.
- Группировка данных: Пространство имен помогает логически группировать и структурировать данные в XML-документе. Оно позволяет создавать собственные пространства имен для элементов и атрибутов, что упрощает организацию данных в иерархическую структуру.
- Расширяемость: Пространство имен обеспечивает расширяемость XML-документов путем добавления новых элементов и атрибутов из дополнительных пространств имен. Это позволяет избежать изменения структуры и синтаксиса существующих данных и облегчает внесение изменений в будущем.
Использование пространства имен в XML-обработке с помощью ElementTree в Python 3 предоставляет удобные и мощные возможности для работы с XML-данными. Оно способствует более гибкой и надежной обработке информации, обеспечивая возможность управлять структурой и содержимым XML-документа.
Как использовать ElementTree для обработки пространства имен в Python 3?
Вот несколько шагов, которые помогут вам использовать ElementTree для обработки пространства имен в Python 3:
1. Импорт модуля ElementTree
import xml.etree.ElementTree as ET
2. Чтение XML-документа
tree = ET.parse('example.xml')
root = tree.getroot()
3. Определение пространства имен
namespace = {'ns': 'http://example.com'}
4. Поиск элементов с использованием пространства имен
elements = root.findall('ns:element_name', namespace)
5. Получение значений атрибутов с использованием пространства имен
value = element.get('ns:attribute_name', namespace)
При использовании ElementTree для обработки пространства имен в Python 3, помните, что все элементы и атрибуты должны быть указаны с префиксом имен в формате «префикс:имя», чтобы указать соответствующее пространство имен. Также необходимо определить пространство имен, используя словарь с префиксами и URI, связанными с ними.
Теперь вы знаете, как использовать ElementTree для обработки пространства имен в Python 3. Не бойтесь задавать свои префиксы и URI для создания более точных и структурированных XML-документов!
Установка библиотеки ElementTree
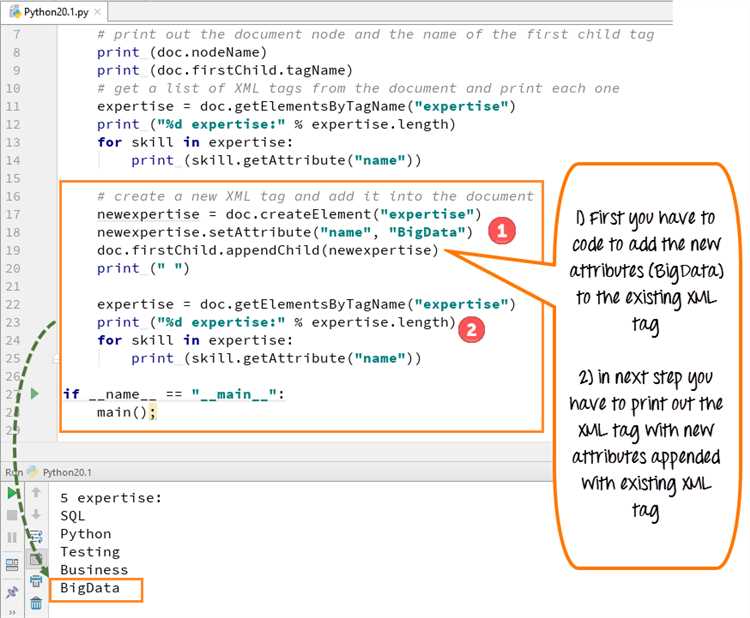
Библиотека ElementTree входит в стандартную библиотеку Python, поэтому нет необходимости устанавливать ее отдельно.
Однако, если вы используете устаревшую версию Python или хотите обновить ElementTree, вы можете установить ее с помощью менеджера пакетов pip. Для этого выполните следующую команду в командной строке:
- pip install elementtree
После установки библиотеки ElementTree вы сможете использовать ее в своих проектах для удобной обработки и анализа XML-документов.
Загрузка и парсинг XML-файла с помощью ElementTree
Для начала работы с XML-файлом необходимо его загрузить при помощи функции etree.parse(). Данная функция принимает в качестве аргумента путь к XML-файлу и возвращает объект ElementTree, представляющий структуру документа.
Пример использования:
import xml.etree.ElementTree as etree
# Загрузка XML-файла
tree = etree.parse("example.xml")
# Получение корневого элемента
root = tree.getroot()
# Дальнейшие операции с XML-документом ...
После загрузки файла можно выполнять различные операции с его содержимым. Например, получить доступ к элементам и их атрибутам, добавить новые элементы, изменить значения атрибутов и т. д.
Пример доступа к элементам XML:
# Получение всех элементов с определенным тегом
elements = root.findall("tag_name")
# Получение значения атрибута у элемента
attribute_value = element.get("attribute_name")
# Перебор дочерних элементов с определенным тегом
for child in element.findall("child_tag"):
# ...
ElementTree также предлагает возможность производить поиск элементов с помощью XPath, что позволяет удобно фильтровать и выбирать необходимые элементы из документа.
Пример использования XPath:
# Получение всех элементов с определенным атрибутом
elements = root.findall(".//*[@attribute_name='value']")
# Получение первого элемента с определенным тегом
element = root.find(".//tag_name")
После выполнения всех необходимых операций с XML-документом изменения можно сохранить обратно в файл с помощью метода tree.write():
# Сохранение изменений в XML-файл
tree.write("modified.xml")
ElementTree является удобным инструментом для работы с XML-файлами в Python. Он предоставляет простой и интуитивно понятный интерфейс, позволяющий эффективно обрабатывать документы и работать с их содержимым.
Извлечение данных из XML-файла с пространством имен
Пространства имен в XML позволяют уникально идентифицировать элементы и атрибуты. Когда XML-файл содержит пространство имен, извлечение данных из него может стать сложной задачей. Однако, с помощью модуля ElementTree в Python 3, можно легко обрабатывать XML-файлы с пространством имен.
Для извлечения данных из XML-файла с пространством имен сначала необходимо указать пространство имен при разборе файла. Затем можно использовать методы ElementTree, такие как find или iterfind, чтобы найти и извлечь определенные элементы или атрибуты.
Например, чтобы найти и извлечь значение атрибута «title» из элемента с пространством имен «book», можно использовать следующий код:
import xml.etree.ElementTree as ET
# Разбор XML-файла
tree = ET.parse('books.xml')
root = tree.getroot()
# Указание пространства имен
namespace = {'ns': 'http://example.com/books'}
# Нахождение и извлечение значения атрибута
title = root.find('ns:book', namespace).attrib['title']
print(title)
Таким же образом можно извлечь значения других элементов или атрибутов с пространством имен. Методы find и iterfind позволяют указывать путь к элементу с пространством имен с использованием префикса пространства имен, указанного при разборе файла.
Используя модуль ElementTree, вы можете легко извлекать данные из XML-файлов с пространством имен, делая обработку XML-данных в Python 3 еще более удобной и эффективной.
