

Python — один из самых популярных языков программирования в мире. Он широко используется для разработки разнообразных приложений, включая обработку и анализ данных. Однако, при работе с большими объемами данных возникают проблемы, связанные с их фрагментацией и рекомбинацией.
Когда мы имеем дело с данными, которые не могут быть полностью загружены в память компьютера, мы вынуждены работать с ними по частям. Это может быть неудобно, особенно если нам нужно объединить эти фрагменты данных в одно целое.
Проблема рекомбинации фрагментированных данных возникает при разделении больших файлов на маленькие части или при обработке данных, которые хранятся в удаленных источниках. Результатом такой операции может быть необходимость собрать эти фрагменты данных обратно в одно целое, чтобы дальше проводить необходимые операции.
В данной статье мы рассмотрим причины, по которым возникают проблемы с рекомбинацией фрагментированных данных в Python, а также познакомимся с решениями данной проблемы. Мы рассмотрим различные способы объединения фрагментов данных, включая использование стандартных библиотек Python и сторонних модулей. Полученные знания помогут вам более эффективно работать с фрагментированными данными и избежать проблем, связанных с их рекомбинацией.
- Работа с фрагментированными данными в Python
- Проблема фрагментации данных в Python
- Причины возникновения проблем с рекомбинацией данных
- Решения проблем с рекомбинацией данных
- Использование функции для рекомбинации фрагментированных данных
- Анализ и обработка фрагментированных данных с помощью библиотеки Pandas
Работа с фрагментированными данными в Python
Первый способ — использование списков. Мы можем создать список, в который будем добавлять фрагменты данных. Затем, для обработки данных, мы можем пройтись по этому списку и собрать все фрагменты в исходный вид.
Второй способ — использование словарей. Если данные разбиты на фрагменты и каждый фрагмент имеет уникальный идентификатор, мы можем создать словарь, где ключом будет идентификатор, а значением — фрагмент данных. Затем мы можем объединить все фрагменты в исходный вид, используя ключи словаря.
Третий способ — использование функций. Мы можем создать функцию, которая будет собирать фрагменты данных в исходный вид. Эта функция может принимать фрагменты данных в качестве аргументов и возвращать исходный вид данных.
Итак, в Python есть несколько способов работы с фрагментированными данными. Каждый из этих способов имеет свои преимущества и подходит для различных сценариев использования.
Проблема фрагментации данных в Python
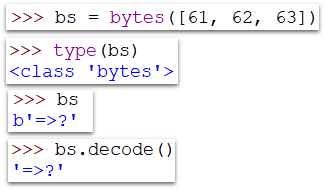
Проблема фрагментации данных может возникнуть по разным причинам. Некоторые из них включают недостаточное количество памяти, ограничения на размер файла или ограничения на передачу данных. Когда данные разделены на фрагменты, становится сложнее собрать их обратно и выполнить нужные операции.
Одно из решений проблемы фрагментации данных в Python — это использование структур данных, таких как списки или массивы. Эти структуры данных позволяют хранить и организовывать фрагменты данных в удобной форме. Кроме того, они предоставляют методы и функции для работы с фрагментированными данными, такие как сортировка, фильтрация и слияние.
Еще одно решение — использование специализированных библиотек и инструментов для работы с фрагментированными данными. Например, модуль itertools предоставляет функциональные возможности для итерирования по комбинациям и перестановкам фрагментов данных. Библиотеки, такие как pandas и numpy, предоставляют эффективные методы работы с массивами и таблицами данных.
В конечном счете, решение проблемы фрагментации данных в Python зависит от конкретной ситуации и требований проекта. Но важно понимать, что существуют различные инструменты и подходы, которые могут помочь упорядочить и объединить фрагментированные данные, облегчая их анализ и обработку.
Причины возникновения проблем с рекомбинацией данных
Проблемы с рекомбинацией фрагментированных данных в Python могут возникать по разным причинам. Рассмотрим некоторые из них:
| 1 |
Неправильная фрагментация данных |
| 2 |
Отсутствие информации о порядке фрагментов |
| 3 |
Передача фрагментов данных в неправильной последовательности |
| 4 |
Потеря фрагментов данных в процессе передачи |
| 5 |
Неправильная обработка фрагментов данных при рекомбинации |
Все эти причины могут привести к тому, что рекомбинация фрагментированных данных будет невозможна или приведет к некорректным результатам. Для успешной рекомбинации данных необходимо тщательно следить за правильностью фрагментации и последовательностью передачи данных, а также обеспечивать надежность и целостность передачи данных.
Решения проблем с рекомбинацией данных
Рекомбинация данных может представлять собой сложную задачу, особенно при работе с фрагментированными данными в Python. Однако, существуют несколько решений, которые могут помочь вам справиться с этой проблемой и успешно рекомбинировать данные.
Первым решением является использование методов объединения данных, таких как `join()` или `concatenate()`. Эти методы позволяют вам объединить фрагментированные данные вместе, создавая один общий массив или строку. Они особенно полезны при работе с массивами или строками данных, которые можно легко объединить.
Еще одним решением может быть использование словаря или списка, чтобы объединить фрагментированные данные в более структурированную форму. Вы можете создать пустой словарь или список и затем добавлять фрагменты данных в него по мере необходимости. Подобный подход позволяет создать более удобное хранилище для ваших данных и использовать их в будущем.
Если вам нужно рекомбинировать более сложные данные, такие как объекты или классы, вы можете использовать механизм сериализации и десериализации. Python предоставляет различные инструменты для сериализации данных, например, модули `pickle` или `json`, которые позволяют сохранить объекты в файл, а затем восстановить их при необходимости. Это позволяет сохранить структуру данных и восстановить ее в исходном состоянии.
Использование функции для рекомбинации фрагментированных данных
Проблемы с рекомбинацией фрагментированных данных могут возникать в различных ситуациях, когда требуется объединить несколько отдельных фрагментов в одно целое. Например, при обработке больших объемов данных, которые были разбиты на части для более эффективной обработки или передачи по сети.
Для решения этой проблемы в Python можно использовать специальную функцию, которая позволяет объединить фрагментированные данные в единое целое. Такая функция должна учитывать особенности фрагментации и обеспечивать правильную последовательность объединения фрагментов.
Самый простой способ рекомбинировать фрагменты данных — это использовать оператор «+» для их объединения. Однако этот способ может не работать в случае, если данные были сжаты или зашифрованы до фрагментации. В таких случаях следует воспользоваться специализированной функцией.
Например, в Python для рекомбинации фрагментированных данных можно использовать функцию recombine_data. Она принимает список фрагментов данных в качестве аргумента и возвращает объединенные данные.
def recombine_data(fragments):
data = ""
for fragment in fragments:
data += fragment
return data
В данной функции используется цикл, который проходит по всем фрагментам данных и объединяет их в одну строку. Результатом работы функции будет строка, содержащая рекомбинированные данные.
Однако стоит отметить, что использование данной функции предполагает, что фрагменты данных будут переданы в правильной последовательности. В противном случае, результатом работы функции может быть неверно объединенная последовательность данных.
Важно учитывать также особенности фрагментирования данных. Например, если данные были сжаты или зашифрованы, необходимо применить соответствующие алгоритмы дешифрования или декомпрессии данных перед их рекомбинацией.
Анализ и обработка фрагментированных данных с помощью библиотеки Pandas
Одна из основных возможностей Pandas — это объединение фрагментированных данных в одну таблицу. Для этого можно использовать функцию concat, которая позволяет объединить несколько таблиц по определенной оси (например, по строкам или по столбцам). Это особенно удобно при анализе данных, которые были разбиты на несколько частей.
После объединения данных в одну таблицу, можно проводить различные анализы и обработку. Например, можно вычислить среднее значение по столбцу, найти максимальное и минимальное значение, или сгруппировать данные по определенному признаку и провести анализ на основе этих групп. Все эти операции легко выполняются с помощью Pandas.
Также библиотека Pandas предоставляет мощные инструменты для фильтрации данных, поиска и замены значений, агрегации данных, работы с пропущенными значениями и другими типами данных, такими как даты и времена.
Одним из преимуществ работы с фрагментированными данными с использованием Pandas является то, что она предоставляет удобный интерфейс и мощные функции, которые позволяют существенно ускорить анализ и обработку данных. Однако, для достижения наилучших результатов, необходимо учитывать особенности структуры и характера данных, а также правильно задать параметры для выполнения операций.
