

Python — один из самых популярных языков программирования, который предлагает множество инструментов для работы с данными. Одной из самых полезных возможностей Python является его способность парсить веб-страницы, то есть получать и обрабатывать данные с Интернета.
Чаще всего парсинг веб-страницы используется для извлечения информации, которая может быть полезной в различных ситуациях. Например, вы можете собирать данные для анализа рынка, мониторинга цен, отслеживания новостей или даже для создания своей собственной базы данных. Благодаря возможностям Python, этот процесс становится гораздо более простым и эффективным.
Однако, чаще всего веб-страницы содержат много данных, и нам необходимо указать, какую именно информацию необходимо получить. Поэтому Python предоставляет возможность ввода пользовательских запросов. То есть, вы можете задавать вопросы и получать информацию, которая соответствует вашим требованиям. Например, вы можете указать, что вам нужны только новости определенной тематики или информация о товарах в определенном диапазоне цен.
Python предоставляет множество библиотек и инструментов для парсинга веб-страниц, например BeautifulSoup, Scrapy, Selenium и многие другие. В зависимости от ваших потребностей и опыта, вы можете выбрать наиболее подходящий для вас инструмент. Однако, что бы вы ни выбрали, Python дает вам возможность легко и эффективно обрабатывать веб-страницы и получать необходимую информацию с минимальными усилиями.
- Парсинг веб-страниц с вводом пользователя на Python
- Удобный способ обработки данных
- Что такое парсинг?
- Преимущества использования Python для парсинга
- Как использовать пользовательский ввод в парсинге
- Как работает парсинг веб-страниц на Python
- Выбор библиотеки для парсинга
- Синтаксис парсинга веб-страницы на Python
Парсинг веб-страниц с вводом пользователя на Python
Парсинг веб-страниц — это процесс извлечения информации с веб-страниц, чтобы использовать ее в дальнейшем анализе, обработке или сохранении. Python предлагает несколько библиотек, таких как BeautifulSoup, для работы с HTML и XML-структурами, упрощающих процесс парсинга веб-страниц.
Чаще всего, веб-страницы содержат информацию, которая часто меняется или обновляется, и необходимость в парсинге веб-страниц с вводом пользователя на Python может возникнуть, когда необходимо извлечь данные с нескольких страниц или выполнить разные действия для разных пользователей.
Особенно полезна возможность ввода пользователя при работе с динамическими веб-страницами, которые обновляются через JavaScript или Ajax. Пользователь может указать параметры для запроса или выбрать определенные элементы на странице для получения нужных данных.
Python предоставляет множество инструментов для работы с пользовательским вводом, таких как библиотека argparse, которая позволяет определить и обработать аргументы командной строки. Таким образом, пользователь может ввести необходимые параметры и персонализировать процесс парсинга.
Кроме того, Python имеет библиотеки для работы с формами на веб-страницах, такие как Selenium, которые позволяют автоматизировать взаимодействие с веб-страницами, включая ввод данных пользователем. С помощью Selenium пользователь может программно заполнять поля формы и отправлять запросы на сервер для получения нужных данных.
Парсинг веб-страниц с вводом пользователя — удобный способ обработки данных и получения нужной информации с веб-страниц. Python предоставляет множество инструментов и библиотек для работы с веб-страницами и пользовательским вводом, что делает процесс парсинга гибким и удобным для пользователей.
Удобный способ обработки данных
Python предоставляет широкий набор инструментов для парсинга веб-страниц с вводом пользовательских данных, что делает его удобным способом обработки данных. Вместо того, чтобы вручную копировать и вставлять информацию из веб-страниц, можно написать скрипт на Python, который автоматически соберет нужные данные.
Один из самых популярных модулей для парсинга веб-страниц — BeautifulSoup. Он позволяет легко находить нужные элементы на странице и извлекать из них информацию. Также с помощью Beautiful Soup можно собирать данные со множества страниц и сравнивать их между собой.
Важным этапом парсинга является ввод пользовательских данных. Python позволяет считывать пользовательский ввод с помощью функции input(). Это особенно полезно при парсинге страниц, где пользователь должен ввести данные для получения результата. Например, при парсинге погодных данных, пользователь может ввести название города, для которого он хочет получить прогноз.
Python также поддерживает работу с различными типами данных, что делает его удобным для обработки и анализа данных. С помощью библиотеки Pandas можно легко работать с таблицами и выполнять различные операции, такие как сортировка, фильтрация и агрегация данных. Это помогает сделать обработку данных более эффективной и удобной.
В итоге, Python предоставляет удобный и мощный инструментарий для обработки данных при парсинге веб-страниц с вводом пользователя. Он позволяет автоматизировать процесс сбора данных и анализировать их в удобном формате. Это делает Python одним из лучших выборов для задач парсинга и обработки данных.
Что такое парсинг?
HTML-страницы состоят из различных элементов, таких как заголовки, текст, изображения, таблицы и пр. Парсинг позволяет извлечь определенные данные, такие как текст, ссылки, таблицы или изображения из HTML-страницы и использовать их для различных целей.
Для парсинга веб-страниц с использованием языка программирования Python существует несколько библиотек, таких как BeautifulSoup, lxml, requests и пр., которые позволяют получить доступ к HTML-коду страницы, извлечь необходимые данные и сохранить их в удобном формате, таком как CSV или JSON.
Парсинг веб-страниц с вводом пользователя — это удобный способ обработки данных, который позволяет автоматизировать процесс получения и анализа информации с веб-сайтов. Он может быть использован для создания поисковых систем, мониторинга цен, сбора данных для аналитики и многих других задач.
| Преимущества парсинга |
|---|
| 1. Автоматизация получения данных. |
| 2. Быстрое извлечение нужных данных. |
| 3. Удобная структуризация данных. |
| 4. Возможность обработки больших объемов информации. |
Преимущества использования Python для парсинга
|
1. Простота и удобство использования. |
Python имеет простой и понятный синтаксис, что делает его легким в освоении даже для начинающих программистов. Благодаря богатому набору библиотек, таких как BeautifulSoup и requests, Python позволяет легко и эффективно выполнять парсинг веб-страниц. |
|
2. Мощные инструменты для парсинга. |
Python предлагает множество библиотек для парсинга, которые обладают широкими возможностями. Например, библиотека BeautifulSoup позволяет легко находить и извлекать нужные данные из HTML-кода веб-страницы, а библиотека requests упрощает получение HTML-кода страницы. |
|
3. Поддержка различных типов данных. |
Python поддерживает работу с различными типами данных, что делает его универсальным инструментом для парсинга. Он позволяет удобно обрабатывать текстовую информацию, изображения, таблицы, JSON и другие данные. |
|
4. Возможность автоматизации. |
Python позволяет автоматизировать процесс парсинга веб-страниц. Используя различные библиотеки и инструменты, можно написать скрипты, которые будут выполнять парсинг множества страниц или регулярно обновлять данные. |
|
5. Богатое сообщество и обширная документация. |
Python имеет активное сообщество разработчиков, которое постоянно создает и поддерживает библиотеки и инструменты для парсинга. Кроме того, в сети можно найти множество документаций, учебников и примеров кода, что делает изучение Python и парсинга простым и доступным. |
В итоге, использование Python для парсинга веб-страниц является удобным и эффективным решением, позволяющим легко обрабатывать и извлекать нужную информацию. Благодаря простоте языка, мощным инструментам и активному сообществу, Python стал популярным инструментом для парсинга.
Как использовать пользовательский ввод в парсинге
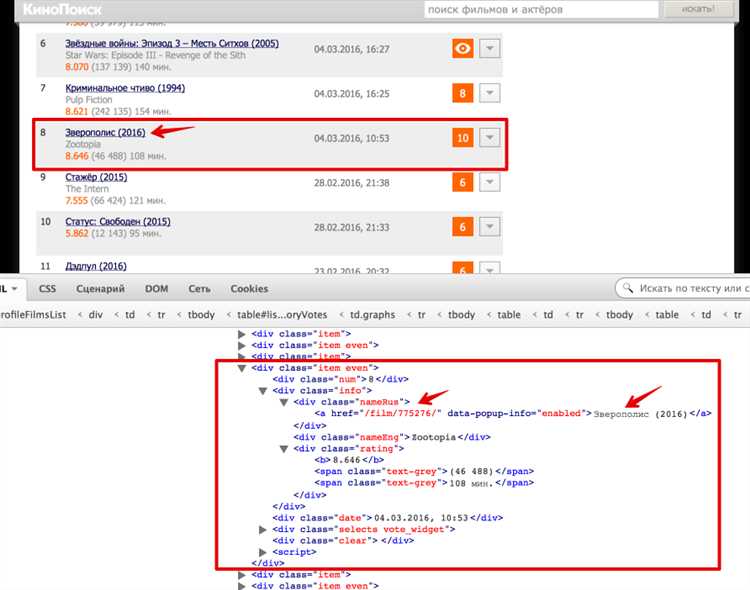
Первый способ — использовать встроенную функцию input(). С помощью этой функции можно запросить у пользователя данные, которые могут быть использованы в парсинге. Например, пользователь может указать URL-адрес веб-страницы, которую нужно распарсить:
url = input("Введите URL-адрес веб-страницы: ")
После получения URL-адреса можно использовать его в парсинге с помощью библиотеки BeautifulSoup или других инструментов для парсинга.
Второй способ — использовать внешние библиотеки для получения пользовательского ввода. Например, веб-приложение Flask предоставляет возможность создания интерактивных веб-страниц с формами, где пользователь может вводить данные. После отправки формы, данные могут быть переданы в парсинговый скрипт для обработки.
Третий способ — использовать командную строку или аргументы командной строки для передачи пользовательского ввода. Это может быть полезно при автоматизации парсинга или при запуске скрипта из командной строки. Например, можно передать URL-адрес веб-страницы как аргумент командной строки:
import sys
url = sys.argv[1]
В зависимости от вашей задачи и предпочтений, вы можете выбрать наиболее удобный способ использования пользовательского ввода в парсинге веб-страниц. Главное — убедитесь, что ваши скрипты корректно обрабатывают пользовательский ввод и предоставляют ожидаемые результаты.
Как работает парсинг веб-страниц на Python
Для парсинга веб-страниц на Python в первую очередь необходим доступ к странице, которую необходимо спарсить. Для этого можно использовать модуль requests. Он позволяет отправлять HTTP-запросы и получать ответы от сервера. С помощью этого модуля можно легко получить содержимое веб-страницы.
После получения содержимого страницы необходимо ее обработать с помощью специальных инструментов. Наиболее популярной библиотекой для парсинга HTML-кода является BeautifulSoup. Эта библиотека позволяет выполнять поиск по HTML-разметке с помощью CSS-селекторов. Она позволяет легко извлекать нужные данные из HTML-структуры.
В разметке веб-страницы данные обычно представлены в виде тегов, атрибутов и текста. В процессе парсинга можно извлекать эти данные с помощью соответствующих методов и функций. Например, с помощью метода find_all() можно найти все элементы с определенным тегом или атрибутом.
Python также поддерживает регулярные выражения, которые могут быть использованы для парсинга веб-страниц. Регулярные выражения позволяют искать и извлекать текст по определенным шаблонам.
Важно помнить, что парсинг веб-страниц может быть ограничен авторскими правами или пользовательскими соглашениями веб-сайтов. Поэтому перед парсингом рекомендуется ознакомиться с правилами использования контента и получить разрешение, если это необходимо.
Выбор библиотеки для парсинга
При парсинге веб-страниц с использованием Python существует множество библиотек, которые могут помочь вам в этом процессе. Выбор правильной библиотеки играет важную роль в том, насколько эффективно и удобно вы сможете обработать данные.
Beautiful Soup является одной из самых распространенных библиотек для парсинга веб-страниц в Python. Она обладает простым и интуитивно понятным API, который позволяет легко находить и извлекать нужные вам элементы страницы. Beautiful Soup также хорошо справляется с разбором HTML и XML документов.
lxml является еще одной популярной библиотекой для парсинга веб-страниц. Она предоставляет высокую производительность и широкий функционал. Lxml может парсить как HTML, так и XML документы, а также работать с XPath, что делает его мощным инструментом для обработки данных.
Requests является библиотекой, которая упрощает выполнение HTTP запросов и взаимодействие с веб-серверами. Она позволяет получить содержимое веб-страницы и передать его на вход другим библиотекам для дальнейшего парсинга. Requests делает процесс парсинга более удобным и эффективным.
Selenium — это инструмент для автоматизации веб-браузера, который может быть использован для парсинга веб-страниц, взаимодействия с JavaScript и выполнения действий пользователя на странице. Selenium может быть полезным, если веб-страница использует JavaScript для динамического обновления контента. Он позволяет имитировать действия пользователя и получать актуальное содержимое страницы.
В конечном счете, выбор подходящей библиотеки для парсинга зависит от ваших нужд и предпочтений. Возможно, вам понадобится комбинация нескольких библиотек для достижения желаемого результата. Чтобы выбрать наиболее подходящую, рекомендуется прочитать документацию и посмотреть примеры использования каждой библиотеки.
Синтаксис парсинга веб-страницы на Python
Для парсинга веб-страницы на Python можно использовать различные библиотеки, такие как Beautiful Soup, lxml или Requests-HTML. В этом разделе мы рассмотрим синтаксис парсинга веб-страницы на Python с использованием библиотеки Beautiful Soup.
Первым шагом необходимо установить библиотеку Beautiful Soup, используя команду pip:
pip install beautifulsoup4Затем, чтобы начать парсить веб-страницу, нужно импортировать класс BeautifulSoup из библиотеки:
from bs4 import BeautifulSoupДалее необходимо получить HTML-код веб-страницы, с которой мы хотим работать. Для этого можно использовать библиотеку Requests:
import requests
response = requests.get(url)
html_code = response.textЗатем создаем объект BeautifulSoup с помощью полученного HTML-кода:
soup = BeautifulSoup(html_code, 'html.parser')Теперь мы можем использовать различные методы для обращения к элементам веб-страницы и получения необходимой информации. Например, для получения текста всех заголовков на странице можно воспользоваться следующим кодом:
headings = soup.find_all('h1')
for heading in headings:
print(heading.text)Аналогично, для получения текста всех абзацев на странице можно использовать следующий код:
paragraphs = soup.find_all('p')
for paragraph in paragraphs:
print(paragraph.text)Также можно использовать фильтры и атрибуты для более точного поиска элементов на странице. Например, чтобы найти все ссылки с определенным классом, можно использовать следующий код:
links = soup.find_all('a', class_='my-class')Это лишь некоторые примеры возможностей и синтаксиса парсинга веб-страницы на Python с использованием библиотеки Beautiful Soup. С помощью этой мощной библиотеки вы сможете получать и обрабатывать любую информацию со страницы в удобном формате.
| Метод | Описание |
|---|---|
| soup.find_all(tag_name, attrs) | Находит все элементы с указанным тегом и атрибутами |
| soup.find(tag_name, attrs) | Находит первый элемент с указанным тегом и атрибутами |
| element.text | Возвращает текстовое содержимое элемента |
| element.get(attr_name) | Возвращает значение указанного атрибута элемента |
| element.find_all(tag_name, attrs) | Находит все дочерние элементы с указанным тегом и атрибутами |
| element.find(tag_name, attrs) | Находит первый дочерний элемент с указанным тегом и атрибутами |
