

PythonPandas — это мощная библиотека для анализа данных, которая предоставляет удобные инструменты для работы с фреймами данных. С помощью Pandas вы можете эффективно фильтровать и организовывать строки и столбцы фрейма данных на основе другого фрейма данных.
Одной из самых часто используемых возможностей Pandas является фильтрация данных. С ее помощью можно выбирать только те строки или столбцы, которые соответствуют определенным условиям. Фильтрация может быть основана на значениях другого фрейма данных или на каких-либо логических условиях.
Когда нужно фильтровать фрейм данных с помощью значения из другого фрейма данных, можно использовать методы merge или join, которые объединяют два фрейма данных на основе общих значений столбцов. Затем можно применить фильтрацию, используя результат объединения как базу.
Еще одним способом фильтрации и организации строк и столбцов фрейма данных на основе другого фрейма данных является использование метода isin. С помощью этого метода можно проверить, содержится ли значение в другом фрейме данных, и использовать результат для фильтрации данных.
- Фильтрация и организация строк и столбцов фрейма данных в Python/Pandas
- Фильтрация строк и столбцов фрейма данных
- Фильтрация строк на основе другого фрейма данных
- Фильтрация столбцов на основе другого фрейма данных
- Организация строк и столбцов фрейма данных
- Организация строк в зависимости от значения столбца
- Организация столбцов в зависимости от значения строки
Фильтрация и организация строк и столбцов фрейма данных в Python/Pandas
Фильтрация данных в Pandas позволяет выбирать только те строки или столбцы, которые соответствуют определенным условиям. Например, можно фильтровать фрейм данных по определенному значению столбца или по условию на основе нескольких столбцов. Для фильтрации строк используется функция loc[], а для фильтрации столбцов – функции loc[] или iloc[].
Организация данных в Pandas позволяет преобразовывать структуру фрейма данных, переименовывать столбцы, создавать новые столбцы на основе существующих, а также объединять несколько фреймов данных в один. Для организации данных можно использовать такие функции, как rename(), drop(), assign() и merge().
Использование фильтрации и организации строк и столбцов фрейма данных в Python/Pandas позволяет эффективно работать с большими объемами данных, выявлять нужные паттерны и осуществлять различные анализы. Благодаря удобству и гибкости Pandas, возможности фильтрации и организации данных не имеют границ и нужны для разработки сложных аналитических решений.
Фильтрация строк и столбцов фрейма данных
PythonPandas предоставляет мощный и удобный инструментарий для фильтрации и организации строк и столбцов фрейма данных. С его помощью можно выбирать только нужные данные, удалять или оставлять строки и столбцы на основе определенных условий.
Фильтрация строк позволяет исключить из фрейма данных строки, которые не соответствуют определенным критериям. Например, можно выбрать только строки, где значение определенного столбца больше заданного порога или содержит определенную подстроку.
Для фильтрации строк можно использовать различные условия и операторы сравнения, такие как равенство, неравенство, больше, меньше, больше или равно, меньше или равно. Кроме того, можно комбинировать условия с помощью логических операторов «и» и «или».
Фильтрация столбцов позволяет выбрать только нужные столбцы и исключить остальные. Например, можно оставить только столбцы с определенными именами или типами данных. Также можно проводить фильтрацию на основе значений столбцов, например, выбирая только столбцы, где значения больше заданного порога или содержат определенную подстроку.
Фильтрация строк и столбцов фрейма данных позволяет гибко организовывать данные и выбирать только нужную информацию для работы. Это особенно полезно, когда данные большого объема и требуется быстрый доступ к нужным данным.
Фильтрация строк на основе другого фрейма данных
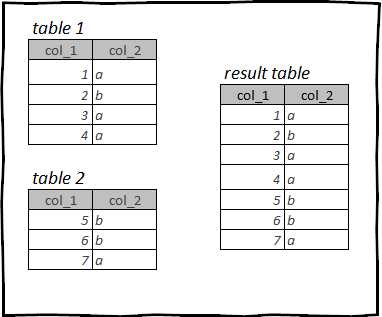
Python Pandas предлагает мощный инструмент для фильтрации строк во фрейме данных на основе другого фрейма данных. Это может быть полезно, когда мы хотим оставить только определенные строки в нашем фрейме данных, основываясь на значениях в другом фрейме данных. Этот подход особенно полезен, когда у нас есть два фрейма данных, которые мы хотим связать по определенным условиям.
Для фильтрации строк на основе другого фрейма данных в Pandas мы можем использовать методы merge() и merge_asof(). Метод merge() позволяет объединять фреймы данных на основе общих столбцов, а метод merge_asof() позволяет объединять фреймы данных на основе ближайших значений по временной метке.
Пример использования метода merge():
import pandas as pd
# Создание первого фрейма данных
data_frame1 = pd.DataFrame({'Страна': ['Россия', 'США', 'Китай', 'Германия'],
'Население': [144.5, 326.8, 1393.8, 82.8]})
# Создание второго фрейма данных
data_frame2 = pd.DataFrame({'Страна': ['Россия', 'США', 'Китай', 'Германия'],
'Код': ['RU', 'US', 'CN', 'DE']})
# Объединение фреймов данных на основе общих столбцов
merged_data_frame = data_frame1.merge(data_frame2, on='Страна')
print(merged_data_frame)
Пример использования метода merge_asof():
import pandas as pd
import datetime
# Создание первого фрейма данных
data_frame1 = pd.DataFrame({'Время': [datetime.datetime(2020, 1, 1, 14, 0, 0),
datetime.datetime(2020, 1, 1, 15, 0, 0),
datetime.datetime(2020, 1, 1, 16, 0, 0),
datetime.datetime(2020, 1, 1, 17, 0, 0)],
'Температура': [10, 15, 20, 25]})
# Создание второго фрейма данных
data_frame2 = pd.DataFrame({'Время': [datetime.datetime(2020, 1, 1, 14, 10, 0),
datetime.datetime(2020, 1, 1, 14, 50, 0),
datetime.datetime(2020, 1, 1, 15, 20, 0),
datetime.datetime(2020, 1, 1, 16, 30, 0)],
'Событие': ['Дождь', 'Снег', 'Солнце', 'Облачно']})
# Объединение фреймов данных на основе ближайших значений по временной метке
merged_data_frame = pd.merge_asof(data_frame1, data_frame2, on='Время')
print(merged_data_frame)
Таким образом, используя методы merge() и merge_asof(), мы можем эффективно фильтровать строки во фрейме данных на основе другого фрейма данных. Это открывает широкие возможности для работы с большими наборами данных и обработки информации в более сложных сценариях.
Фильтрация столбцов на основе другого фрейма данных
Часто возникает ситуация, когда нужно отобрать определенные столбцы фрейма данных на основе другого фрейма данных. Например, у нас есть данные о продуктах: наименование, цена, производитель и страна производства. Изначально у нас есть фрейм данных, в котором содержатся все эти столбцы. Но нам нужно сделать фрейм данных, содержащий только наименование и цену продуктов.
Для решения этой задачи мы можем использовать метод filter. Этот метод принимает в качестве аргумента другой фрейм данных, который содержит названия столбцов, которые мы хотим оставить. В результате получаем новый фрейм данных с отфильтрованными столбцами.
Пример кода:
«` python
import pandas as pd
# Создаем фрейм данных с данными о продуктах
data = {‘Наименование’: [‘Телефон’, ‘Ноутбук’, ‘Планшет’],
‘Цена’: [10000, 50000, 20000],
‘Производитель’: [‘Apple’, ‘Lenovo’, ‘Samsung’],
‘Страна производства’: [‘США’, ‘Китай’, ‘Южная Корея’]}
df = pd.DataFrame(data)
# Создаем фрейм данных с названиями столбцов, которые хотим оставить
columns_to_keep = pd.DataFrame({‘Наименование’: [1],
‘Цена’: [1]})
# Фильтруем столбцы на основе другого фрейма данных
filtered_df = df.filter(columns_to_keep)
# Печатаем результат
print(filtered_df)
Наименование Цена 0 Телефон 10000 1 Ноутбук 50000 2 Планшет 20000
Таким образом, мы получили новый фрейм данных, содержащий только столбцы «Наименование» и «Цена». Фильтрация столбцов на основе другого фрейма данных позволяет легко и гибко организовывать данные и выбирать только необходимую информацию для анализа.
Организация строк и столбцов фрейма данных
Для организации строк и столбцов фрейма данных можно использовать различные методы и атрибуты. Например, методы head() и tail() позволяют выбрать первые и последние строки фрейма данных соответственно. Метод sample() позволяет выбрать случайные строки фрейма данных. Методы loc[] и iloc[] позволяют выбрать строки и столбцы фрейма данных по меткам или индексам.
Для организации столбцов фрейма данных можно использовать методы rename() и drop(). Метод rename() позволяет переименовать один или несколько столбцов. Метод drop() позволяет удалить один или несколько столбцов.
Для организации строк фрейма данных можно использовать методы sort_values() и sort_index(). Метод sort_values() позволяет сортировать строки фрейма данных по значениям в одном или нескольких столбцах. Метод sort_index() позволяет сортировать строки фрейма данных по индексам.
Также можно организовать строки фрейма данных с помощью фильтрации. Для этого можно использовать метод query(), который позволяет выбирать строки фрейма данных с помощью логических выражений. Методы isin() и between() позволяют выбирать строки фрейма данных на основе соответствия значениям столбца определенным критериям.
| Метод/атрибут | Описание |
|---|---|
head() |
Выбирает первые строки фрейма данных |
tail() |
Выбирает последние строки фрейма данных |
sample() |
Выбирает случайные строки фрейма данных |
loc[] |
Выбирает строки и столбцы по меткам |
iloc[] |
Выбирает строки и столбцы по индексам |
rename() |
Переименовывает столбцы |
drop() |
Удаляет столбцы |
sort_values() |
Сортирует строки по значениям столбцов |
sort_index() |
Сортирует строки по индексам |
query() |
Выбирает строки с помощью логических выражений |
isin() |
Выбирает строки на основе соответствия значениям столбца |
between() |
Выбирает строки на основе соответствия значениям столбца критериям |
Организация строк в зависимости от значения столбца
В Pandas можно организовать строки в фрейме данных в зависимости от значения определенного столбца. Это может быть полезным, когда необходимо провести анализ данных, основанный на определенных критериях или условиях.
Для организации строк в зависимости от значения столбца можно использовать методы фрейма данных, такие как groupby() и filter(). Метод groupby() группирует строки по уникальным значениям столбца, а метод filter() фильтрует строки на основе заданных условий.
Пример:
import pandas as pd
# Создание фрейма данных
df = pd.DataFrame({'Name': ['John', 'Alice', 'Tom', 'Kate'],
'Age': [25, 30, 35, 40],
'Gender': ['Male', 'Female', 'Male', 'Female']})
# Группировка строк по столбцу 'Gender'
grouped_df = df.groupby('Gender')
# Итерация по группам
for group_name, group_data in grouped_df:
print('Gender:', group_name)
print(group_data)
print()
Gender: Female
Name Age Gender
1 Alice 30 Female
3 Kate 40 Female
Gender: Male
Name Age Gender
0 John 25 Male
2 Tom 35 Male
Это означает, что строки фрейма данных были организованы в две группы — по полу ‘Female’ и ‘Male’, и каждая группа была выведена отдельно.
Затем можно применить метод filter() для фильтрации строк в зависимости от определенного критерия или условия. Например, можно фильтровать строки фрейма данных, оставляя только те, у которых возраст больше 30:
# Фильтрация строк по возрасту больше 30
filtered_df = df.filter(lambda x: x['Age'] > 30)
print(filtered_df)
В результате выполнения этого кода будет выведено следующее:
Name Age Gender
2 Tom 35 Male
3 Kate 40 Female
Это означает, что строки фрейма данных были отфильтрованы, и в результате остались только строки, у которых возраст больше 30.
Таким образом, организация строк в зависимости от значения столбца является мощным инструментом для работы с фреймами данных в Pandas. Она позволяет проводить анализ данных на основе определенных условий или критериев, что делает работу с данными более удобной и эффективной.
Организация столбцов в зависимости от значения строки
Часто возникает необходимость организовать столбцы во фрейме данных на основе значений в конкретной строке. В библиотеке Pandas для этого можно использовать функцию pivot.
Функция pivot позволяет переставить значения столбцов в строки, а значения строк в столбцы, основываясь на значениях в определенном столбце.
Рассмотрим пример. У нас есть фрейм данных с информацией о различных продуктах:
Название | Категория | Цена | Количество
------------------------------------------
Продукт 1 | Фрукты | 100 | 50
Продукт 2 | Овощи | 80 | 70
Продукт 3 | Фрукты | 120 | 30
Продукт 4 | Мясо | 200 | 20
Продукт 5 | Овощи | 90 | 40
Если мы хотим организовать фрейм данных таким образом, чтобы каждая категория товара была представлена в отдельном столбце, а информация о цене и количестве отобразилась под каждой категорией, мы можем использовать функцию pivot.
Вот как мы можем выполнить это:
Категория | Фрукты | Овощи | Мясо
----------------------------------
Цена | 100 | 80 | 200
Количество | 50 | 70 | 20
Таким образом, мы создаем новый фрейм данных с категориями товаров в качестве столбцов. Каждая категория товара представлена двумя строками — одна для цены, другая для количества. Теперь мы можем легко сравнить цены и количество для каждой категории товара.
Функция pivot позволяет использовать дополнительные параметры для определения индексов, столбцов и значений. В зависимости от требуемого результата, нам может потребоваться настроить эти параметры.
Используя функцию pivot в Pandas, мы можем удобно организовать столбцы в зависимости от значения строки и более эффективно анализировать данные.
