

Apache Spark — это мощный фреймворк для обработки больших данных, который широко используется в современном анализе данных. Однако, взаимодействие между Spark, Hadoop, Scala, Java и Python может вызывать ряд проблем совместимости, которые могут затруднить процесс разработки и выполнения задач.
Совместимость Spark и Hadoop — один из основных вопросов, с которым сталкиваются разработчики. Spark работает на платформе Hadoop и может использовать его в качестве распределенной файловой системы. Однако, версии Spark и Hadoop должны быть совместимы, иначе могут возникнуть проблемы совместимости, такие как ошибки чтения и записи данных.
Одно из решений этой проблемы — это установка совместимых версий Spark и Hadoop. Рекомендуется использовать последние стабильные версии фреймворков и регулярно обновляться, чтобы избежать проблем совместимости и воспользоваться новыми функциональными возможностями.
Совместимость Spark с языками программирования также вызывает определенные сложности. Spark поддерживает несколько языков программирования, таких как Scala, Java и Python. Однако, нет гарантии, что код, написанный на одном языке, будет работать без ошибок на другом языке.
Для решения этой проблемы необходимо быть внимательным при использовании различных языков. Необходимо учитывать особенности каждого языка и адаптировать код соответствующим образом, чтобы обеспечить его совместимость. Также рекомендуется тестировать код на различных языках, чтобы выявить и исправить возможные проблемы совместимости до внедрения в продакшн.
- Проблемы совместимости между Spark, Hadoop, Scala, Java и Python
- Проблемы взаимодействия между Spark и Hadoop
- Необходимость совместимых версий
- Конфликты при использовании разных библиотек
- Проблемы совместимости с различными форматами данных
- Проблемы совместимости между Scala и Java
- Различия в синтаксисе и структуре кода
- Конфликты при использовании разных версий Java
- Проблемы совместимости между Python и Scala/Java
Проблемы совместимости между Spark, Hadoop, Scala, Java и Python
При разработке и использовании больших данных сталкиваются с проблемами совместимости между различными компонентами, такими как Spark, Hadoop, Scala, Java и Python. Несмотря на то, что эти инструменты позволяют эффективно обрабатывать и анализировать данные, возникают некоторые трудности при их интеграции и взаимодействии.
Одной из главных проблем является совместимость версий различных компонентов. Новые версии Spark или Hadoop могут быть несовместимы с предыдущими версиями, что может вызывать проблемы при развертывании и выполнении приложений. Кроме того, существуют различия в языковой поддержке, так как Spark поддерживает Scala, Java и Python, но не все функции доступны на каждом языке. Это может привести к проблемам при разработке и исполнении кода на разных языках программирования.
Другой проблемой является совместимость с файловыми форматами. Например, Spark может быть интегрирован с Hadoop, но может быть затруднено взаимодействие с файлами в формате Avro или Parquet. В таких случаях могут потребоваться дополнительные адаптации или конвертация данных для совместимости между разными форматами.
Также возникают проблемы совместимости между различными типами данных, особенно при работе с данными на языке Scala и Python. Некоторые операторы или функции могут работать неодинаково для разных типов данных или могут не поддерживаться на выбранном языке. Это может привести к ошибкам выполнения или неправильной интерпретации результатов.
Решение этих проблем включает в себя тщательное тестирование и анализ совместимости между компонентами перед их использованием. Необходимо убедиться, что все компоненты работают вместе корректно и поддерживают требуемые функции и форматы данных. Кроме того, следует быть внимательными к версиям компонентов и выполнять обновления, когда это необходимо, чтобы избежать проблем совместимости.
В целом, проблемы совместимости между Spark, Hadoop, Scala, Java и Python являются распространенной проблемой при разработке и использовании инструментов анализа данных. Однако с тщательным тестированием, анализом и обновлениями можно достичь успешной интеграции и взаимодействия между этими компонентами для обработки и анализа больших объемов данных.
Проблемы взаимодействия между Spark и Hadoop
Взаимодействие между Apache Spark и Apache Hadoop имеет свои особенности, которые могут вызывать проблемы при использовании этих технологий вместе.
Одной из главных проблем является интеграция Spark и Hadoop в единую экосистему. Spark использует собственные API и интерфейсы для работы с данными и параллельных вычислений, в то время как для взаимодействия с Hadoop требуется использовать другие библиотеки и инструменты.
Также возникают проблемы совместимости версий между Spark и Hadoop. Разные версии этих двух фреймворков могут иметь несовместимые изменения в API и внутренних структурах данных, что может привести к ошибкам или непредсказуемому поведению системы.
Еще одной проблемой может быть отсутствие поддержки определенных функций или возможностей Spark или Hadoop. Например, некоторые функции, доступные в Spark, могут быть недоступны в Hadoop или работать некорректно из-за отличий в реализации.
Важно также помнить о различиях в языках программирования. Spark поддерживает несколько языков программирования, таких как Scala, Java, Python и R, в то время как Hadoop предлагает преимущественно язык Java. При реализации проекта на Spark с использованием других языков может возникнуть необходимость в дополнительных решениях и настройках.
Для решения проблем взаимодействия между Spark и Hadoop рекомендуется использовать совместимые версии этих фреймворков, следить за обновлениями и исправлениями, а также анализировать документацию и сообщества пользователей для поиска решений и советов.
Также, стоит рассмотреть возможность использования специальных инструментов, таких как Hadoop-Spark Connector, который облегчает интеграцию и взаимодействие между Spark и Hadoop, упрощая передачу данных и выполнение вычислений.
Необходимость совместимых версий
При разработке и запуске приложений на основе Spark рекомендуется использовать совместимые версии всех необходимых компонентов. Это обеспечивает стабильную работу программы и минимизирует риск возникновения проблем.
Проверить совместимость версий можно, выполнив следующие действия:
- Определить требования к версиям Spark, Hadoop, Scala, Java и Python, указанные в документации каждого из этих инструментов.
- Установить необходимые версии компонентов в соответствии с требованиями.
- Проверить работу программы на совместимость и отсутствие ошибок.
Если в процессе работы вы обнаружите несовместимость версий, рекомендуется обновить компоненты до совместимых версий или найти альтернативные решения, которые позволят обеспечить совместимость.
Необходимость совместимых версий является важным аспектом при работе с технологиями Spark, Hadoop, Scala, Java и Python. Следование рекомендациям по совместимости поможет избежать непредвиденных проблем и обеспечить эффективную работу программы.
Конфликты при использовании разных библиотек
Конфликты могут возникать, например, при использовании разных версий Hadoop. Spark поддерживает разные версии Hadoop, но при несовпадении версий могут появиться проблемы с совместимостью. Возможный вариант решения — использование совместимых версий Hadoop и Spark или выполнение необходимых настроек для совместимости между ними.
Также могут возникать проблемы при использовании разных версий Scala, Java и Python. Несовместимость версий может привести к ошибкам во время компиляции и выполнения кода. Для решения этой проблемы рекомендуется использовать совместимые версии языков и указывать зависимости в проекте с учетом совместимости версий.
Кроме того, конфликты могут возникать при использовании разных библиотек для работы с данными, таких как Apache Avro, Apache Parquet и других. При несовместимости версий и зависимостей этих библиотек могут возникать ошибки при чтении, записи и обработке данных. Необходимо убедиться, что используемые библиотеки совместимы между собой и выполнить необходимые настройки и обновления.
Важно помнить, что при использовании разных библиотек и зависимостей необходимо внимательно следить за их совместимостью, регулярно обновлять и проверять версии, а также выполнять необходимые настройки для предотвращения конфликтов. Тщательное планирование и тестирование помогут избежать возможных проблем и обеспечить успешное взаимодействие между Spark, Hadoop, Scala, Java и Python.
Проблемы совместимости с различными форматами данных
Например, Spark поддерживает работу с такими форматами как CSV, JSON, Avro, Parquet и др. Однако, если данные, с которыми мы хотим работать, хранятся в другом формате, то возникают проблемы со совместимостью. Необходимо преобразовывать данные в формат, поддерживаемый Spark, что может занимать дополнительное время и ресурсы.
Также возникают проблемы связанные с тем, что различные инструменты имеют разное представление данных. Например, в Scala данные могут быть представлены в виде объектов, в Java — в виде классов, а в Python — в виде словарей или списков. Это может создавать сложности при передаче данных между различными инструментами и требовать дополнительной обработки и преобразования.
Однако, с развитием и появлением различных библиотек и инструментов, разработчики стараются упростить процесс работы с различными форматами данных и обеспечить их совместимость. Например, существуют библиотеки для работы с различными форматами данных, такие как Apache SerDe для работы с CSV, JSON и Avro, и Apache Parquet для работы с форматом Parquet.
Также можно использовать инструменты для преобразования данных, например, Apache NiFi, Apache Kafka или Apache Flink, которые позволяют легко передавать данные между различными форматами.
Важно также знать особенности работы с каждым конкретным инструментом и форматом данных, чтобы избежать проблем совместимости и эффективно использовать возможности каждого инструмента.
Проблемы совместимости между Scala и Java
Одной из основных проблем является различие в синтаксисе и структуре языков. Scala, будучи более выразительным и гибким языком, имеет некоторые особенности, которые не совместимы с Java. Например, в Scala нет понятия «статического» класса, поэтому нельзя напрямую обращаться к статическим методам и полям Java класса из Scala кода.
Еще одной проблемой является несовместимость некоторых библиотек и фреймворков, написанных на Java, с Scala. Некоторые Java API могут иметь ограничения, которые не позволяют использовать их в Scala коде без дополнительного преобразования или обертки.
Кроме того, Scala и Java имеют разные системы типов, что может приводить к проблемам совместимости. Некоторые типы данных, которые являются стандартными в Java, могут быть неявно преобразованы в Scala, но не всегда это преобразование будет безопасным и корректным.
Решить проблемы совместимости между Scala и Java можно с помощью использования библиотек, которые обеспечивают мост между этими языками. Например, библиотека Scala Java-Interop предоставляет средства для взаимодействия между Scala и Java кодом, решая многие проблемы совместимости.
Также, для улучшения совместимости между языками, важно иметь хорошее понимание особенностей обоих языков и принципов работы с ними. Это позволяет избегать ошибок, связанных с нечетким пониманием синтаксических и структурных различий.
В итоге, хотя Scala и Java оба являются мощными языками программирования, существуют проблемы совместимости между ними. Однако, эти проблемы могут быть решены с помощью соответствующих библиотек и хорошего понимания особенностей обоих языков.
Различия в синтаксисе и структуре кода
Spark поддерживает несколько языков программирования, включая Scala, Java и Python. Однако, у этих языков существуют некоторые различия в синтаксисе и структуре кода, которые необходимо учитывать при разработке приложений на Spark.
Scala является языком программирования, совместимым с Spark, который предоставляет наиболее полные и мощные возможности для работы с ним. Код на Scala обычно выглядит более компактно и выразительно по сравнению с Java и Python. Однако, для работы с Scala необходимо иметь определенные знания и навыки.
Java является одним из основных языков программирования, с которым Spark совместим. Код на Java часто выглядит более объемным и немного сложнее читать, но он обладает высокой производительностью и надежностью. Для работы с Java в Spark также необходимы определенные знания и навыки.
Python является еще одним языком программирования, который можно использовать с Spark. Он обладает простым и интуитивно понятным синтаксисом, что делает его отличным вариантом для новичков или для быстрой разработки прототипов. Однако, из-за динамической типизации Python может иметь некоторые проблемы с производительностью в сравнении с Scala или Java.
При разработке приложений на Spark необходимо учитывать эти различия в синтаксисе и структуре кода для каждого из языков. Кроме того, также следует учитывать особенности работы с библиотеками и инструментами, свойственными каждому языку. Наличие определенных знаний и навыков в этих языках программирования может существенно облегчить работу и повысить эффективность разработки на Spark.
Конфликты при использовании разных версий Java
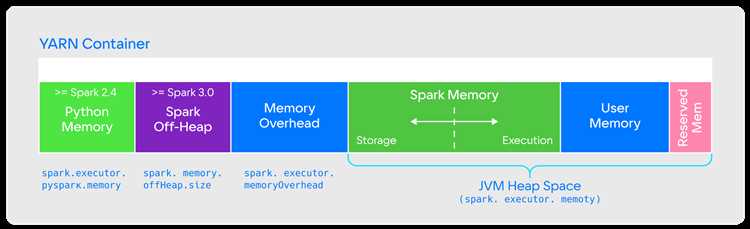
Spark требует определенной версии Java для работы, и если используется неподдерживаемая или несовместимая версия, могут возникать проблемы во время компиляции или выполнения кода.
Возможные конфликты могут возникать, когда разные приложения или компоненты используют разные версии Java. Например, если Spark запущен с использованием Java 8, а другая часть приложения или библиотека работает с Java 7, может возникнуть конфликт во время выполнения.
Одним из решений данной проблемы может быть обновление версии Java для всех компонентов приложения. Также можно использовать инструменты, такие как Maven или Gradle, для управления зависимостями и обеспечить совместимость между разными версиями Java.
Однако, необходимо быть осторожным при обновлении Java, так как некоторые приложения или библиотеки могут быть несовместимы с новыми версиями и требовать обратной совместимости.
Также необходимо помнить о том, что не все функции и возможности Spark могут быть доступны при использовании более старых версий Java. Рекомендуется использовать поддерживаемые и совместимые версии Java, чтобы избежать проблем и обеспечить более стабильную работу приложений.
В целом, конфликты при использовании разных версий Java могут быть решены путем обновления версии Java или управления зависимостями с помощью соответствующих инструментов. Однако, необходимо быть внимательным и проверять совместимость компонентов, чтобы избежать возможных проблем и обеспечить более стабильную работу приложений.
Проблемы совместимости между Python и Scala/Java
Несмотря на то, что Spark предоставляет возможность использовать несколько языков программирования, таких как Python, Scala и Java, иногда могут возникать проблемы связи между ними.
Одной из основных проблем является различие в типах данных между Python и Scala/Java. В Python типы данных определяются автоматически, в то время как в Scala/Java типы данных должны быть объявлены явно. Это может привести к трудностям при передаче данных между двумя языками.
Еще одной проблемой является различие в синтаксисе между Python и Scala/Java. Некоторые функции и методы в Python могут иметь другое название или использоваться иначе в Scala/Java. Это также может вызывать путаницу при попытке передать код между двумя языками.
Кроме того, скорость выполнения кода может отличаться в зависимости от выбранного языка. Scala, являясь статически типизированным языком, может предоставить более высокую производительность по сравнению с Python, который является динамическим языком. Это также может оказать влияние на процесс совместимости между двумя языками.
Для решения этих проблем рекомендуется следующее:
- Явно объявлять типы данных: при передаче данных между Python и Scala/Java рекомендуется явно указывать типы данных для избежания ошибок совместимости.
- Использовать подходящие функции и методы: перед передачей кода между Python и Scala/Java необходимо убедиться, что используемые функции и методы имеют одинаковое название и работают одинаково в обоих языках.
- Оптимизировать производительность: для достижения лучшей производительности рекомендуется использовать Scala, особенно при работе с большими объемами данных.
В целом, совместимость между Python и Scala/Java может быть достигнута при соблюдении рекомендаций по явному указанию типов данных и использованию подходящих функций и методов. Знание особенностей каждого из языков также поможет в решении проблем совместимости и повышении эффективности работы с Apache Spark.
